Appearance
Module 3: Entropy Management 熵管理
最被低估的组件。AI代码库会随时间积累熵。
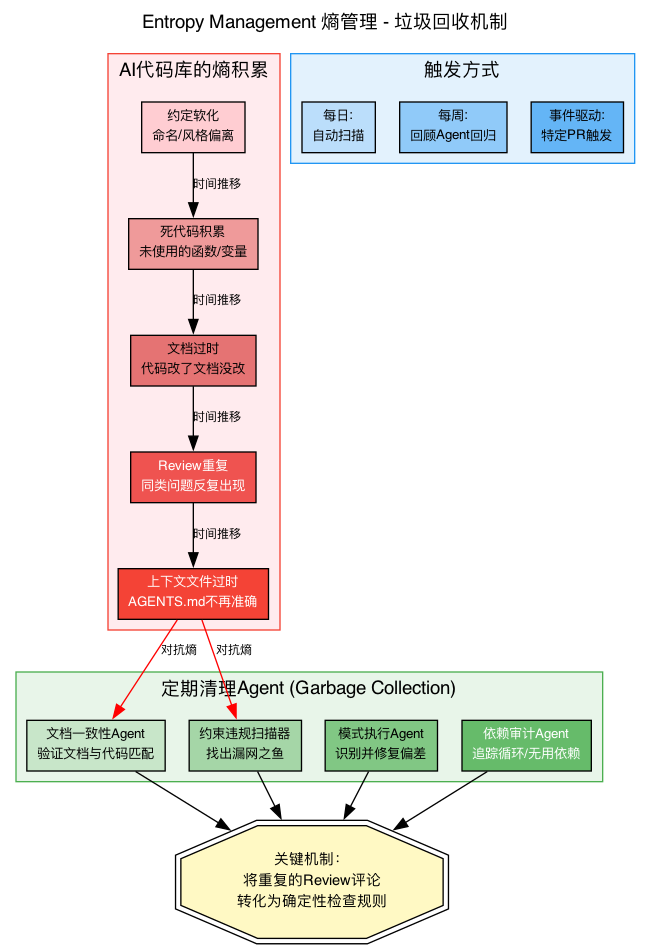
3.1 熵积累过程与对抗机制
📐 查看Graphviz源码 (03-entropy-management.dot)
dot
// 见 dots/03-entropy-management.dot3.2 五种熵退化
| 退化类型 | 表现 | 对抗手段 |
|---|---|---|
| 约定软化 | 命名/风格逐渐偏离 | 模式执行Agent |
| 死代码积累 | 未使用的函数/变量 | 依赖审计Agent |
| 文档过时 | 代码改了文档没改 | 文档一致性Agent |
| Review重复 | 同类问题反复出现 | 转化为确定性规则 |
| 上下文过时 | AGENTS.md不再准确 | 定期清理 |
3.3 关键机制:Review → Rule 转化
这是Harness Engineering最核心的反馈闭环:
发现Agent反复犯同一个错误
→ 不要继续在Review中写评论
→ 将评论转化为Linter规则/CI检查
→ 从此这类错误被自动拦截3.4 实用缓解措施
- 每次有意义的PR: 自动Review
- 高风险场景: 第二个模型交叉审查
- 定期: 清理根指令文件
- 追踪: Agent失败的链路和事后分析
- 转化: 反复出现的Review评论 → 确定性检查
3.5 Eval驱动的Harness持续进化(来自LangChain + Stanford CS230)
Module 0提到Harness有第五层——Improvement Layer。这一节展开讲如何让Harness自己变好。
核心洞察
"Evals是Harness的训练数据。" ——LangChain
传统软件工程的质量保障靠测试。Agent系统的质量保障靠Eval(结构化评测)。区别在于:
| 传统测试 | Eval | |
|---|---|---|
| 输入 | 确定性输入 | 自然语言、多轮对话 |
| 输出 | 确定性断言 | 概率性评分(0-1) |
| 频率 | CI/CD时运行 | 持续运行、每次Harness变更后运行 |
| 目的 | 验证正确性 | 衡量改进幅度、防止退化 |
Harness Hill-Climbing 方法论
LangChain把Harness的改进过程类比为"爬山":
1. 收集Traces(Agent运行的完整日志)
2. 构建Eval(从失败案例提取测试集)
3. 拆分数据(optimization set + holdout set)
4. 修改Harness(改prompt/tools/workflow/约束)
5. 在optimization set上验证改进
6. 在holdout set上确认没有退化
7. 部署 → 收集新Traces → 回到第1步关键纪律:永远留一个holdout set。 如果你只在训练集上"调分",Harness会过拟合到特定场景,遇到新任务就崩。
斯坦福CS230的五层决策树:从简单开始
Andrew Ng和Stanford CS230强调:不要一上来就用最复杂的方案。
| 层级 | 方法 | 何时升级到下一层 |
|---|---|---|
| L1 | Prompt / Few-shot | 单轮指令不够精确时 |
| L2 | Chaining(链式调用) | 单次调用质量不够、需要分步时 |
| L3 | RAG(检索增强) | 模型缺乏领域知识时 |
| L4 | Agent(工具调用+循环) | 需要动态决策和外部操作时 |
| L5 | Multi-Agent | 单Agent能力不够、需要专家协作时 |
贯穿所有层的是Eval: 每一层都需要Eval来判断"当前方案够不够"。如果L1的Eval分数已经满足需求,就不需要升级到L2。
JAG Frontier(判断-行动-生成边界): AI不是万能的。识别AI的能力边界,对边界外的任务保持人类判断,这本身是Harness设计的一部分。
3.6 🔬 Lab 3: 设置熵管理
任务:
- 写一个"文档一致性检查"脚本
- 创建一个Review评论→Lint规则的转化示例
- 设置一个定期清理提醒